


|
|
El propósito al construir este
modelo es determinar las variables que muestran mayor asociación
con la pobreza, no buscándose necesariamente hallar relaciones
de causalidad que permitan explicarla, aspecto que es explorado
en la sección siguiente, sino cuantificar la correlación
que fue observada intuitivamente con el análisis de las
tablas cruzadas. La regresión estimada permitirá
determinar aquellas variables que, después de controlar
los efectos de otras, se correlacionan más con la pobreza.
Para tal efecto se considera al hogar
como la unidad económica relevante y, por tanto, en el
lado izquierdo de la regresión (la variable dependiente)
se toma a la variable dummy que tiene el valor de cero
si el hogar es clasificado como pobre y uno si es como no pobre.
La clasificación de pobre o no pobre se hizo en función
del ingreso percápita familiar, es decir, si estuvo por
debajo o arriba del valor de la Canasta Básica de Consumo
que incluye alimentos y no alimentos (definidos para cada uno
de los dominios geográficos de estudio). El ingreso utilizado
es aquel que resulta de sumar los ingresos del hogar por toda
fuente, los cuales se encuentran detallados en el Anexo C.
El lado derecho de la regresión
(las variables independientes) esta conformado por un conjunto
de variables relacionados con los factores socioeconómicos
y demográficos que caracterizan a los hogares, es decir,
aquellos que fueron utilizados en su gran mayoría en la
determinación del perfil de la pobreza. Como la variable
dependiente es dicotómica, se optó por la función
logística para representar el modelo de regresión.
En consecuencia, se estimó la probabilidad de que un hogar
sea pobre en función de las variables anteriormente indicadas1 .
La estimación de los coeficientes del modelo se hizo utilizando
el método de máxima-verosimilitud controlándose
las variables independientes con el método «forward
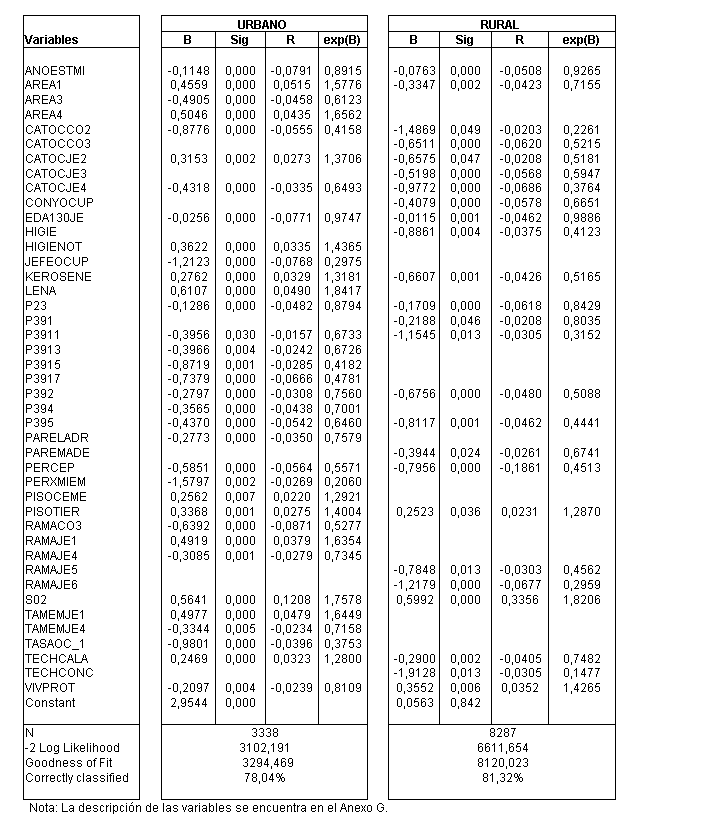
stepwise». Los resultados de la estimación
que se muestran en el Cuadro Nº
26, solo consideran, en consecuencia,
a aquellas variables que son estadísticamente significativas.
En general, puede señalarse que
el poder predictivo del modelo es satisfactorio ya que clasifica
en una proporción importante a los hogares como pobres
cuando el hogar es realmente pobre y como no pobre cuando en realidad
no lo es. La tasa de clasificación correcta es 81 % en
el ámbito urbano y 78 % en el rural. Las pruebas de hipótesis
en torno a los coeficientes de regresión (los estadísticos
«Wald» y «model chi-sq.», este último
que opera de manera semejante a la F2 ) indican que estos
son significativos, es decir, diferentes de cero a un nivel de
confianza de por lo menos el 5 %, y en su gran mayoría
al 1 % para los dos ámbitos.
La evidencia indica que las variables
que se correlacionan con la incidencia de la pobreza generalmente
son distintas en el ámbito urbano y en el rural debido
a que de un total de 43 variables que son significativas en uno
u otro ámbito, solo 16 lo son en ambos, siendo 5 de ellos
de signo contrario.
El Cuadro Nº 26 muestra que tanto
en el ámbito urbano como en el rural:
El Cuadro Nº 26 también
muestra que :
Respecto a las variables que más
se correlacionan con la pobreza, diferentes a las anteriores,
y que solo son significativas en uno de los ámbitos, puede
decirse lo siguiente: