


|
|
7. Anexos ANEXO METODOLOGICO 1. El Universo y Muestra La presente investigación tomó como universo de estudio a la totalidad de la población peruana para los tres años considerados, 1994, 1997 y 1998. Las bases de datos seleccionadas fueron las variables sumarias construídas por el INEI (para el caso de las ENAHO 1997-IV y 1998-IV) y por CUANTO S.A. (para el caso de la ENNIV 1994). Además, para poder estimar la pobreza dividiendo a la población por sectores económicos, utilizamos como variable proxy a la pea ocupada por rama de actividad económica. Por esta razón fue necesario tambien utilizar las bases de datos que correspondían al capítulo del empleo (capítulo 500) de ambas ENAHO (1997-IV y 1998-IV) y la sección correspondiente para el caso de la ENNIV 1994 (sección 5). 2. Definición de Variables y Procedimientos para el Análisis de Datos Resultantes Como ya se señaló, las variables principales de interés fueron: el PBI, la pobreza medida por el ingreso percápita familiar y el empleo. a) PBI Fue necesario disponer de los datos del PBI peruano en sus distintos desagregados: * A nivel nacional, por departamentos. La recopilación de datos para el PBI se hizo en dos fases. Una primera obtenida a partir de los datos proporcionados por el INEI en el libro "Producto Bruto Interno Departamental: 1970-1995." De aquí se recogieron los PBI globales nacionales, por departamento de Lima y por actividad económica únicamente hasta el año de 1995. Para el resto de años (1996-1998) la fuente utilizada fue el "Compendio Estadístico Económico Financiero 1997-1998", en la cual fue posible recopilar la información para el PBI global y por actividad económica mas no en sus desagregados departamentales. Como no se disponía de los PBI desagregados a nivel departamental ni tampoco de acuerdo a sus actividades económicas, se procedió a hacer estimaciones de los mismos con la estructura dada por la serie de datos disponible de 1970-1995. Sin embargo, fue necesario antes de ello, definir la variable Resto del País, resultante de la estimación que se hiciera para el departamento de Lima a partir de los datos globales. Teniendo en cuenta esto, el mejor arreglo de datos estimados fue alcanzado con un ajuste cuadrático que estandarizamos para todos los desagregados necesarios. Este trabajo es simplificado por el uso del programa informático MS Excel (tanto en la versión 95 como 97). Se seleccionan la serie de datos para un sector dado. Luego, se plotea en un gráfico de puntos (XY Dispersión). Posteriormente, se seleccionan los datos en el gráfico realizado y se selecciona la opción del menú contextual llamada 'linea de tendencia', tipo 'Polinomial' de segundo grado. Por último, se activa la opcion 'Presentar la ecuación en el gráfico' . Esto nos da la ecuación de ajuste buscada. Las estimaciones logradas fueron: * PBI departamental de Lima para 1997 y 1998. A partir de estas estimaciones fue entonces posible tambien construir la data para el resto del país por simple diferencia con la estructura global del PBI. Una vez realizado esto, se procedió a seleccionar los años que competían para el análisis realizado en el presente estudio, es decir: 1994, 1997 y 1998. Cruzando esta información con los resultados de las estimaciones logradas de las bases de datos ENNIV 1994 y ENAHO 1997-IV y 1998-IV, se calcularon: * PBI percápita 1994, 1997 y 1998 global, a nivel de departamento de Lima y Resto del País y por actividad económica. Este ultimo resultado es la información preliminar necesaria para el cálculo de las elasticidades. b) POBREZA Por el lado de la Pobreza, interesó que esta fuera calculada por el nivel de ingreso familiar percápita. Esto es asi por el vínculo directo que representa con el empleo, aun cuando puedan existir algunas sobreestimaciones al tener conocimiento de otras fuentes de ingresos que no son propiamente laborales. En todo caso, la variable de ingreso familiar percápita mensual (definida como 'ingper' para todas las bases usadas) fue calculada a partir de la variable de ingreso familiar total, haciendo las siguientes precisiones. Para la base de la ENNIV de 1994, fue necesario solamente dividir el ingreso familiar por el número de personas que conformaban dicho hogar. Para el caso de las ENAHO 1997-IV y ENAHO 1998-IV fue necesario dividir los ingresos familiares totales entre tres ya que estos están registrados por trimestre y luego entre el número de personas que conformaban dicho hogar. A partir de este cálculo se creó la variable "pobing" (pobreza según el ingreso) en todas las bases de datos. Esta contendría la etiqueta para identificar los niveles de pobreza según el ingreso percápita. El script utilizado para realizar tal operación en el programa SPSS 7.5, es como sigue (se da el ejemplo solamente para el caso de Lima, ENAHO 1997-IV): IF ((DOMINIO = 8) & (ingper < 109.10)) pobing = 1 . IF ((DOMINIO = 8) & (ingper >= 109.10) & (ingper < 213.63)) pobing = 2 . IF ((DOMINIO = 8) & (ingper >= 213.63)) pobing = 3 . EXECUTE . val label pobing 1 pobre extremo End. Este procedimiento fue repetido para cada uno de los dominios, considerando previamente lo siguiente: Como existieron problemas para identificar los dominios rurales de los no rurales, ya que la disponibilidad de las canastas por dominio diferían de la que presenta la base de datos sumaria de la que se encuentra en la publicación de las canastas en el INEI, se procedió a tomar las canastas ponderadas por población por gran dominio. Es decir, se realizó lo siguiente:
El valor de las canastas ponderadas se encuentran en el anexo 04, con los valores utilizados para cada dominio y nivel de pobreza respectivamente. Con estos valores y con el modelo del script mostrado mas arriba se procedió a estimar los niveles de pobreza buscados para la población tanto para el Perú entero como para el caso específico de Lima. Para concluir, se definieron tambien, en el análisis de la pobreza de la población, las siguientes variables: pob125, pob150 y pob 200 para cada una de las bases utilizadas. Esta construcción fue necesaria en virtud de poder calcular los rangos de población que se encuentran entre 1.00 y 1.25 canastas básicas de consumo, 1.25 y 1.50 canastas básicas de consumo, 1.50 y 2.00 canastas básicas de consumo; y 2.00 canastas básicas de consumo a más. El script necesario para el cálculo es parecido al utilizado para el cálculo de la pobreza que es suficiente información para poder reproducir los cálculos necesarios.
c) EMPLEO Esta variable fue identificada a partir de la variable de situación ocupacional (niveles de empleo) identificada por el INEI en la base de datos de las ENAHO 1997-IV y 1998-IV. Como era de nuestro interés, para los fines que persigue el estudio identificar la pobreza por sectores económicos, como una manera de aproximar el vínculo que existe entre el crecimiento económico y la reducción de los niveles de pobreza, esta variable debia ser cruzada con la variable "actividad económica" y como esta variable no podía identificarse por grandes sectores, recurrimos al INEI para que nos proporcionara el script necesario para agruparlos convenientemente. A continuación transcribimos la sintaxis utilizada (se da el ejemplo para el caso de la ENAHO 1998-IV): recode p506 (0100 thru 0499 =1) (0500 thru 0599 =2) (0600 thru 1499 =3) (1500 thru 3799 =4) (4000 thru 4199 =5) (4500 thru 4599 =6) (5000 thru 5099 =7) (5100 thru 5199 =8) (5200 thru 5299 =9) (5500 thru 5599 =10) (6000 thru 6499=11) (6500 thru 6799 =12) (7000 thru 7499 =13) (7500 thru 7599 =14) (8000 thru highest =15) into RAMA . VAL LABEL rama 1 agricultura A partir de esta codificación fue posible obtener lo siguiente: * PEA ocupada a nivel nacional, departamento de Lima y resto del país Sólo fue seleccionada la pea ocupada para los tres años, porque la identificación de los desocupados por sector económico no estaba dada para la ENAHO 1998-IV. Con los resultados obtenidos, cruzamos la información de la PEA ocupada (a través de las variables claves que identifican el hogar: segmento, vivienda, hogar) con la variable POBING de cada una de las bases de datos para poder identificar a la PEA ocupada por niveles de pobreza. Esto se realizó como una forma de poder aproximar el efecto resultante de la actividad económica en cada sector sobre los niveles de la pobreza que muestran los hogares a los cuales representan cada uno de los perceptores de ingreso ocupados. La información obtenida a partir de la base de datos nos permitió obtener los niveles de empleo de la PEA ocupada por actividad económica y por niveles de pobreza. Con estos datos se obtuvieron igualmente, como en el caso del PBI, las variaciones anualizadas para los siguientes periodos, 1997-1994 y 1998-1994. d) ELASTICIDADES Con las variaciones obtenidas de cada uno de las variables procesadas según lo descrito en los apartados anteriores, se procedió a calcular las elasticidades para cada una de las variables estudiadas respecto al PBI, con la siguiente fórmula (reproducida nuevamente): 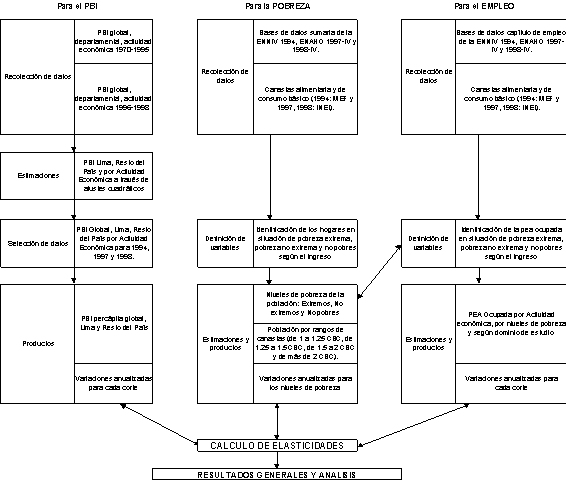 |